My Kubernetes Journey - Episode 0: A Second Shot
(Re)Starting my journey into Kubernetes.

I enjoy building things and exploring new technologies. While I'm not an expert in everything, I'm a fast and practical learner. I specialize in programming with Go (Golang). Additionally, I work as a freelancer on Upwork. If you require assistance or have a job vacancy, feel free to reach out to me.
Disclaimer: The information provided in this series may not be 100% accurate and may be unstructured. This is not a tutorial series; it is meant to document my learnings. If you happen to be interested in reading about my journey, stick around.
I haven't touched Kubernetes in about two years now (at the time of writing this blog). The last version of Kubernetes I used was v1.25. I started learning Kubernetes in mid-2022 when the startup I was working for decided to switch to it. It felt shiny and exciting, similar to how I felt when I first started using Linux. However, I lost touch with Kubernetes after I quit my internship and began freelancing. None of my clients had any Kubernetes requirements, and since I wasn't using Kubernetes for hosting my personal projects (because EKS is expensive and my workloads don't need to run on Kubernetes), I drifted away from it.
So, why am I learning Kubernetes again?
There are two reasons:
- I recently deployed an application on Kubernetes for a client, using NGINX ingress, cert-manager, and CI/CD with GitHub Actions. This reignited my motivation to re-learn Kubernetes, in deeper detail this time.
- It's May 2024, and I have just graduated from college. My biggest priority now is getting a job in tech. Kubernetes has exploded in popularity and is used by many companies. As a result, there are jobs offering good packages for Kubernetes engineers.
A Kubernetes engineer? Or should I say a Kubernetes developer/admin or maybe a DevOps engineer? Or for a more sophisticated title, perhaps an SRE? All these cloud-native jobs may have isolated roles and responsibilities on paper. However, in practice, the have a lot of overlap.
Putting My Memory on Paper
Episode 0 is mainly about writing down whatever I know about Kubernetes from memory. Some of the details might be incorrect or contain discrepancies. I also love creating visual sketches using Excalidraw, so I'll be sketching out representations whenever needed or possible.
Kubernetes Architecture

- Broadly, Kubernetes' architecture consists of control plane nodes and worker nodes.
- All the nodes in the cluster run processes called
kubeletandkube-proxy, as well as a container runtime.
Container Runtime
- The most popular container runtime is
containerd, which originated from the Docker project when the Docker team decided to separate the runtime from the Docker tool. - I remember experimenting with
CRI-Otwo years ago when I was deploying a Kubernetes cluster on my Raspberry Pis using an official tool calledkubeadm. - All in all, the container runtime you use shouldn't really matter in terms of actual usage, as all of them are OCI (Open Containers Initiative) compliant.
Kube-Proxy
I know very little about this. All I remember is that it is used to load balance traffic across nodes.
Kubelet
- This is a daemon process that runs on every node in the cluster, including the control-plane nodes.
- The API server communicates what needs to be done to the
Kubelet. TheKubeletis then responsible for conveying these instructions to the container runtime. - Additionally, the
Kubeletmonitors the status of the node and containers and communicates this information back to the API server.
Worker Nodes
- These are physical computers or VMs that run your applications.
- The
scheduler(part of the control-plane) schedules pods to these nodes. - Each worker node can be assigned labels, which the scheduler can use
to limit which nodes a particular group of pods can be deployed to, a
property called
nodeAffinity.
Control-Plane
- This node is responsible for all cluster operations.
- In addition to the
kubelet,kube-proxy, and the container runtime, the control-plane also houses thescheduler,controller manager, and a key-value distributed database calledEtcd. - Recently, I have heard that it possible for the control-plane to run application workloads, although it is advised against doing so in production.
Scheduler
- As discussed above, the scheduler schedules pods to worker nodes. In other words, the scheduler decides where pods needs to be deployed in the cluster.
- I would like to know more about the underlying scheduling algorithm it uses.
Controller Manager
- The controller manager's job is to spawn controllers like
deployments,statefulsets, andreplicasets. These controllers watch for changes to their respective manifests usingEtcd'swatching ability. - When a change occurs, such as modifying a deployment's YAML file, the
controller picks it up and communicates with the
kubeletvia the API server to converge to the desired state.
Etcd
- Often referred to as the brain of Kubernetes.
- It is a key-value, non-hierarchical database.
- It is distributed and uses the Raft consensus algorithm.
- It provides clients the ability to watch keys and receive updates in the form of events when a key is added, modified, or deleted. This ability forms the basis of Kubernetes' convergence-to-the-desired-state model.
- It is advised to always have an odd number of control-plane nodes (and thus an odd number of Etcd databases, one on each node).
Kubernetes Objects
Pod
- Atomic unit in Kubernetes.
- Houses one (usually) or more containers (sidecar containers).
- Pods are replaceable. If a pod becomes unhealthy or crashes, the replicaset replaces it with a new one.
- An IP address is assigned to each pod by Kubernetes' DNS server (CoreDNS). This IP address may change when a pod is destroyed or replaced.
ReplicaSet
- A level of abstraction on top of pods.
- It is a controller responsible for maintaining a desired number of pod replicas.
Deployment
- A level of abstraction on top of replicasets.
- It provides complex features like auto-scaling, rollbacks, and zero-downtime updates. I have very little understanding of how to configure these features.
 Credits: @antweiss on X
Credits: @antweiss on X
Service
- A service is an abstraction on top of the
Endpointsobject. I don't remember much about the Endpoint object beyond its name. - It provides a persistent address to your pods and load balances traffic across them.
- A service can be of one of 3 types:
- ClusterIP: Internal to the cluster; not accessible from outside.
- NodePort: Accessible on a particular port from any worker node. Note: Firewall rules need to be configured to allow inbound traffic on that port.
- LoadBalancer: Exposed behind a load balancer. In cloud environments like AWS (EKS), a load balancer is automatically assigned when you create the service object.
Ingress
- Ingress allows you to route traffic into your cluster using HTTP paths and domains.
- When using ingress, the service object is usually of type
ClusterIP. - Ingress exposes only HTTP and HTTPS traffic behind a single load balancer, unlike a load balancer service type that exposes any traffic. This reduces costs, as cloud providers charge for each deployed load balancer.
- Since most services are HTTP services, using ingress can significantly reduce costs.
- An Ingress Controller manages ingress objects. I remember deploying an NGINX ingress controller.
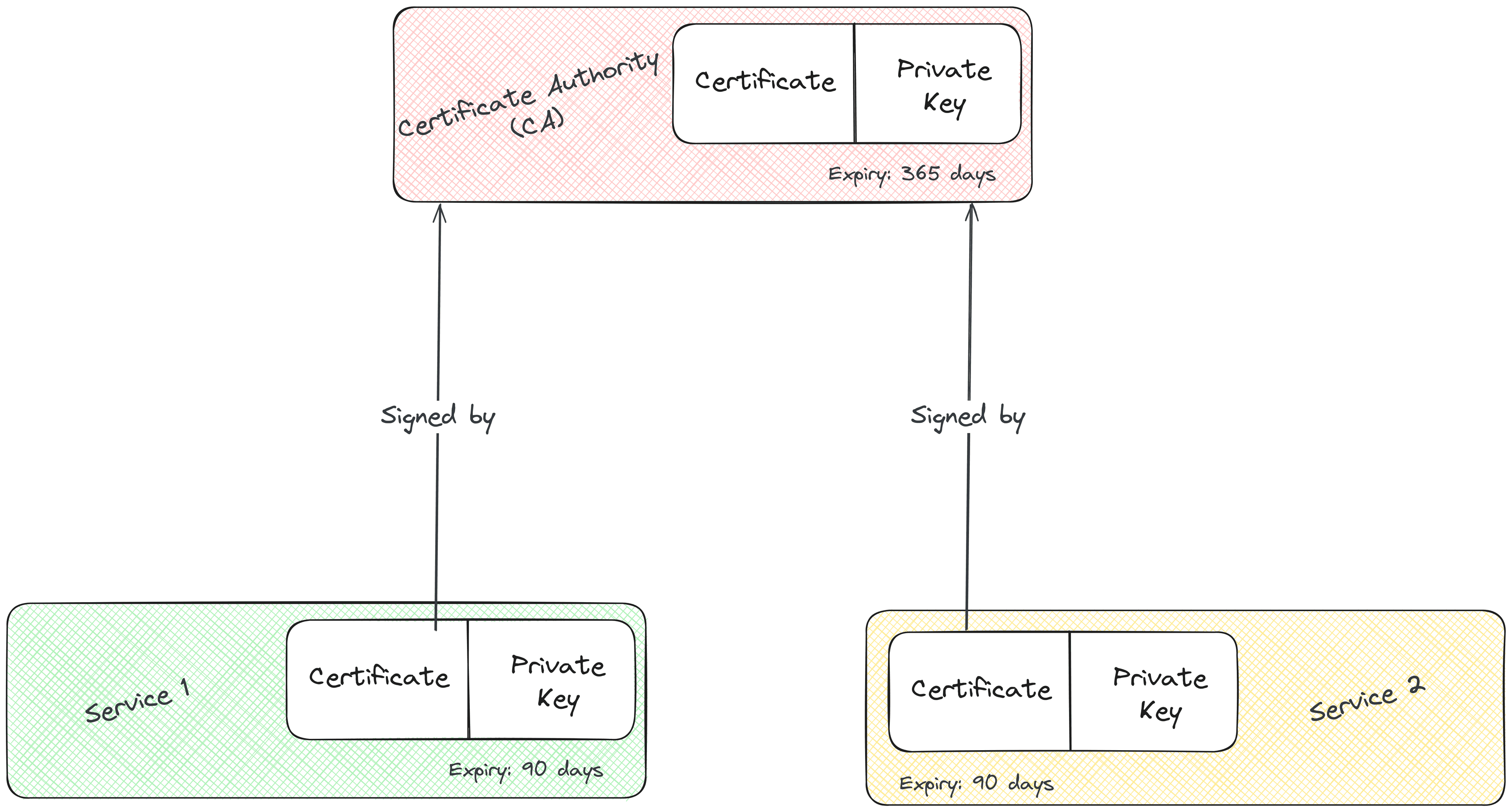
Secrets
- Used to store confidential and sensitive data in Kubernetes.
- I have yet to learn how Kubernetes stores this data securely.
- Secrets can be passed to pods as environment variables or volumes.
ConfigMap
- Similar to secrets, but used to store non-confidential data.
Persistent Volume (PV)
- A data store that can be exposed to pods.
- PVs can be backed by numerous storage options like an NFS share or an AWS EBS volume.
- PVs can be dynamically provisioned or reserved in advance.
Persistent Volume Claim (PVC)
- A claim issued to the API server to bind to a persistent volume.
- These claims can be referenced in deployment YAML files to mount the volume into the pod container's file system.
Storage Classes
- I have sparse memory about this one. To my understanding, this was a way to factor away the definition of the underlying storage (NFS, AWS EBS, etc.) into a reusable component referenced by PVCs.
StatefulSets
- Used to deploy stateful workloads like a database.
- I have hardly worked with statefulsets in the past. To my knowledge, it performs some persistent volume witchcraft. Each statefulset pod is allocated its own PV, which is retained even after the statefulset is deleted. Also, statefulset pods are created and deployed by Kubernetes in a sequential order.
Jobs
- Sometimes you would want to run a one-time task in your Kubernetes cluster. For example, data processing.
- Jobs allows you to run one-time finite tasks in your cluster.
CronJobs
- Like Jobs, but run at regular intervals.
- The cron syntax is exactly same as that of UNIX systems.
Init Containers
Init containers initialize/prepare the environment for the main application container, which runs only after the init container exits with an exit code of 0.
Static Pods
- In Kubernetes, the controller manager, scheduler, API server, and etcd database all run as pods. However, no pods can start without control-plane components, creating a chicken-and-egg problem.
- The solution to the above problem are static pods. Static pods are managed by the kubelet directly. This means that they run independent of the control-plane components.
- During bootstrapping, Kubernetes control plane components are deployed as static pods.
- Static pods are mirrored to the API server, allowing you to see
control-plane components when listing pods in the
kube-systemnamespace. - I have written a twitter thread on static pods: LINK
kubectl get pods -n kube-system
Technologies Around Kubernetes That I've Played With
Talos Linux
- Talos (from SideroLabs) is a secure Kubernetes operating system.
- It lets you interact with your nodes (that have Talos Linux on them) using a gRPC API. Not even an SSH server runs on those nodes.
- I would likely use Talos if I ever run a homelab Kubernetes cluster.
MetalLB
- When running a Kubernetes cluster on metal, you need to set up a load balancer yourself, unlike in cloud environments where it is automatically assigned.
- I remember installing MetalLB as a minikube addon.
Kube VIP
- Kube VIP is another load balancer. I remember using it when I was deploying a HA cluster on-metal.
- Kube VIP provides both a load balancer for services and a high availability virtual IP that load balances across all control-plane nodes.
- I don't remember why I chose Kube VIP over MetalLB.
Could MetalLB not be used for a high-availability cluster to load balance traffic to the control-plane nodes ??
Closing Words
That's all I could recall off the top of my head. For now, I want to focus on reaffirming my Kubernetes knowledge and filling in the gaps. See you in the next episode.
End Credit
I have templates stored for all the Kubernetes objects. I don't remember where I got them from, but they were quite handy.
ConfigMap
kind: ConfigMap
apiVersion: v1
metadata:
name: ${1:myconfig}
namespace: ${2:default}
data:
${3:key}: ${4:value}
---
Secret
apiVersion: v1
kind: Secret
metadata:
name: ${1:mysecret}
namespace: ${2:default}
type: ${Opaque|kubernetes.io/service-account-token|kubernetes.io/dockercfg|kubernetes.io/dockerconfigjson|kubernetes.io/basic-auth|kubernetes.io/ssh-auth|kubernetes.io/tls}
# stringData:
# foo: bar
data:
# Example:
# password: {{ .Values.password | b64enc }}
---
PV
apiVersion: v1
kind: PersistentVolume
metadata:
name: ${1:pvapp}
spec:
capacity:
storage: 1Gi
volumeMode: ${2:Filesystem|Block}
accessModes:
- ReadWriteOnce # RWO
- ReadOnlyMany # ROX
- ReadWriteMany # RWX
- ReadWriteOncePod # RWOP
persistentVolumeReclaimPolicy: ${3:Recycle|Retain|Delete}
storageClassName: default
nfs:
server: 172.17.0.2
path: /tmp
# hostPath:
# path: /path/to/directory
PVC
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: ${1:myapp}
namespace: ${2:default}
labels:
app: ${1:myapp}
spec:
# AKS: default,managed-premium
# GKE: standard
# EKS: gp2 (custom)
# Rook: rook-ceph-block,rook-ceph-fs
storageClassName: ${3|default,managed-premium,standard,gp2,rook-ceph-block,rook-ceph-fs|}
accessModes:
- ${4|ReadWriteOnce,ReadWriteMany,ReadOnlyMany|}
resources:
requests:
storage: ${5:2Gi}
---
Storage Class
# https://kubernetes.io/docs/concepts/storage/storage-classes
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: ${1:standard}
provisioner: ${2:kubernetes.io/aws-ebs|kubernetes.io/azure-disk|kubernetes.io/gce-pd}
parameters:
type: gp2
reclaimPolicy: Retain
allowVolumeExpansion: true
mountOptions:
- debug
volumeBindingMode: Immediate
Deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: ${1:myjob}
namespace: ${2:default}
labels:
app: ${1:myjob}
spec:
selector:
matchLabels:
app: ${1:myjob}
replicas: 1
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
labels:
app: ${1:myjob}
spec:
containers:
- name: ${1:myjob}
image: ${3:myjob:latest}
imagePullPolicy: ${4|IfNotPresent,Always,Never|}
resources:
requests:
cpu: 100m
memory: 100Mi
limits:
cpu: 100m
memory: 100Mi
livenessProbe:
tcpSocket:
port: ${5:80}
initialDelaySeconds: 5
timeoutSeconds: 5
successThreshold: 1
failureThreshold: 3
periodSeconds: 10
readinessProbe:
httpGet:
path: /_status/healthz
port: ${5:80}
initialDelaySeconds: 5
timeoutSeconds: 2
successThreshold: 1
failureThreshold: 3
periodSeconds: 10
env:
- name: DB_HOST
valueFrom:
configMapKeyRef:
name: ${1:myjob}
key: DB_HOST
# optional: true
# envFrom:
# prefix: CONFIG_
# - configMapRef:
# name: myconfig
# optional: true
ports:
- containerPort: ${5:80}
name: ${1:myjob}
volumeMounts:
- name: localtime
mountPath: /etc/localtime
volumes:
- name: localtime
persistentVolumeClaim:
claimName: myclaim
restartPolicy: Always
---
Service
apiVersion: v1
kind: Service
metadata:
name: ${1:myjob}
namespace: ${2:default}
spec:
selector:
app: ${1:myjob}
type: ${3|ClusterIP,NodePort,LoadBalancer|ExternalName|}
ports:
- name: ${1:myjob}
protocol: ${4|TCP,UDP|}
port: ${5:80}
targetPort: ${6:5000}
nodePort: ${7:30001}
---
Ingress
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ${3:tls-example-ingress}
namespace: ${2:default}
spec:
tls:
- hosts:
- ${4:https-example.foo.com}
secretName: ${1:testsecret-tls}
rules:
- host: ${4:https-example.foo.com}
http:
paths:
- path: /${5}
pathType: Prefix
backend:
service:
name: ${6:service1}
port:
number: ${7:80}
---
StatefulSet
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: ${1:myapp}
namespace: ${2:default}
spec:
selector:
matchLabels:
app: ${1:myapp} # has to match .spec.template.metadata.labels
serviceName: ${1:myapp}
replicas: ${3:3} # by default is 1
template:
metadata:
labels:
app: ${1:myapp} # has to match .spec.selector.matchLabels
spec:
terminationGracePeriodSeconds: 10
containers:
- name: ${1:myapp}
image: ${4:${1:myapp}-slim:1.16.1}
ports:
- containerPort: ${5:80}
name: ${1:myapp}
volumeMounts:
- name: ${6:www}
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: ${6:www}
spec:
storageClassName: ${7:my-storage-class}
accessModes:
- ${8|ReadWriteOnce,ReadWriteMany,ReadOnlyMany|}
resources:
requests:
storage: ${9:1Gi}
---
Job
apiVersion: batch/v1
kind: Job
metadata:
name: ${1:myjob}
namespace: ${2:default}
labels:
app: ${1:myjob}
spec:
template:
metadata:
name: ${1:myjob}
labels:
app: ${1:myjob}
spec:
containers:
- name: ${1:myjob}
image: ${3:python:3.7.6-alpine3.10}
command: ['sh', '-c', '${4:python3 manage.py makemigrations && python3 manage.py migrate}']
env:
- name: ENV_NAME
value: ENV_VALUE
volumeMounts:
- name: localtime
mountPath: /etc/localtime
volumes:
- name: localtime
hostPath:
path: /usr/share/zoneinfo/Asia/Taipei
restartPolicy: OnFailure
dnsPolicy: ClusterFirst
---
CronJob
apiVersion: batch/v1
kind: CronJob
metadata:
name: ${1:cronjobname}
namespace: ${2:default}
spec:
schedule: ${3:*/1 * * * *}
jobTemplate:
spec:
template:
spec:
containers:
- name: ${4:jobname}
image: ${5:busybox}
args: ['/bin/sh', '-c', '${6:date; echo Hello from the Kubernetes cluster}']
restartPolicy: OnFailure
---